Sensitive data in.Clean document out.
The engine that recognizes, understands, and censors names, social security numbers, and clinical data in seconds. Sensitive data in, redacted PDF out.
30-minute call. Let's look at your document workflow together.
Every redaction tool obscures names. Most obscure the wrong ones too.
Standard PII detectors are blind to context. They find patterns, they don't understand meaning. Feed them a medical report and they'll obscure the patient's name. Feed them a historical essay and they'll obscure Napoleon too. This isn't redaction. It's guessing with a marker.
Standard Redactor
Removes both private data and historical context, rendering the text incomprehensible.
ObscuraDoc
Protects patient identity while safely preserving historical references.
ObscuraDoc reads before redacting.
Our pipeline combines Named Entity Recognition (NER) with contextual classification. Every candidate entity is evaluated based on surrounding context before anything is removed. Public figures stay. Historical references stay. Private citizens do not. The result is a clean document, not a damaged one.
Upload
Drag and drop your PDF or DOCX. No data is stored on our servers.
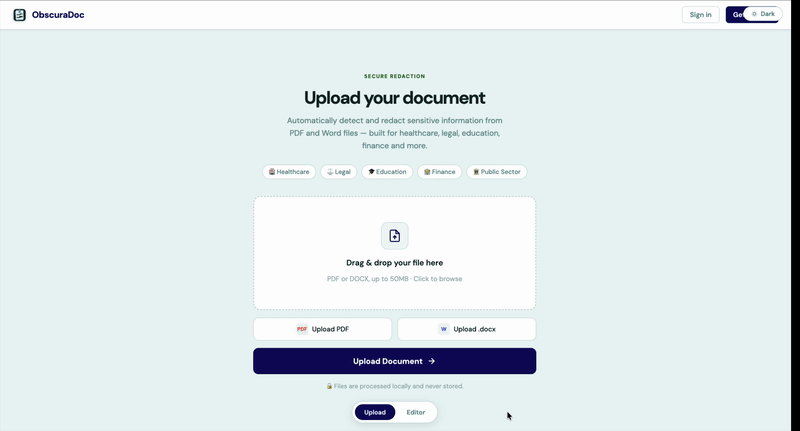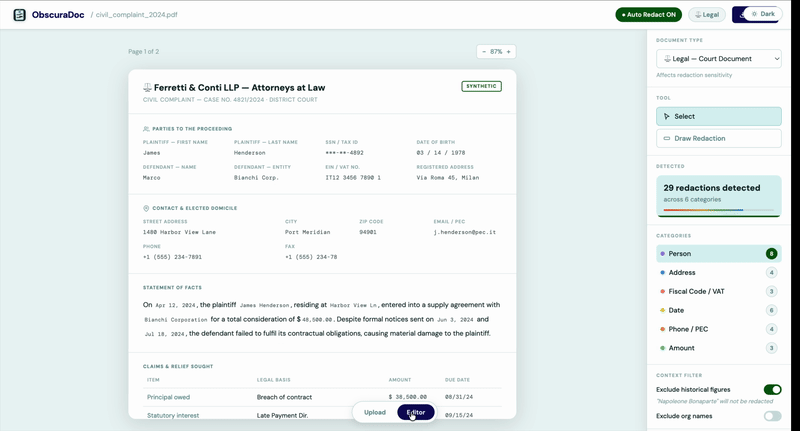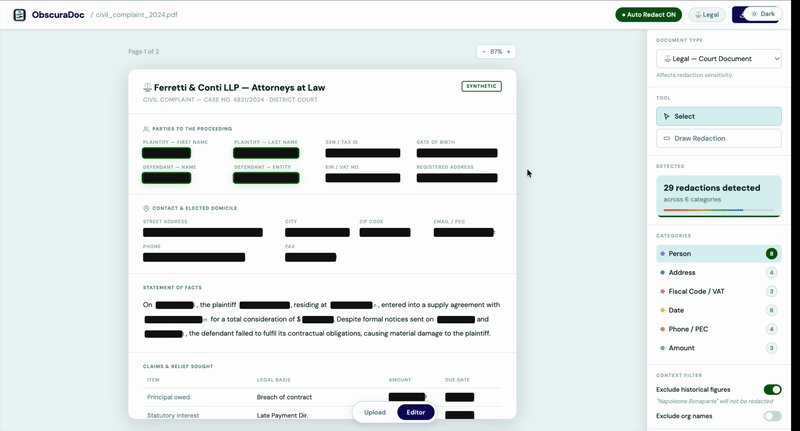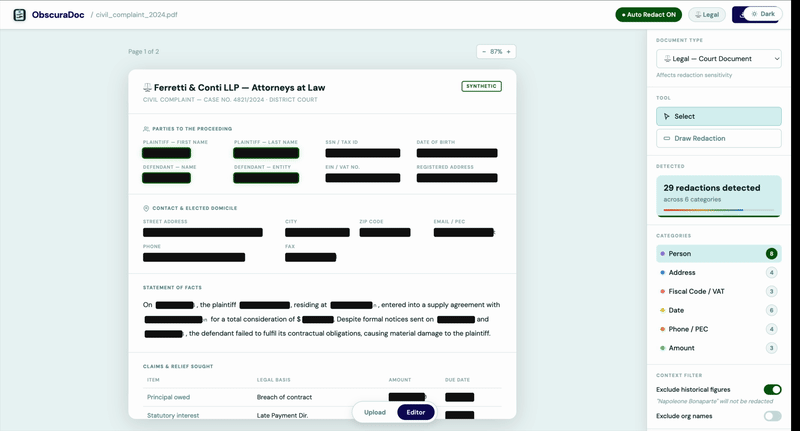
Review
ObscuraDoc highlights every detected entity and its classification. You approve, edit, or override before a single letter is removed.
Download
Get your redacted document. We only keep an encrypted map of the coordinates, so you can reapply the same redactions later without re-uploading the data.
Everything you need, without compromise.
Intelligent Contextual Classification
Powered by a multi-stage pipeline, NER, LLM contextual classification, and conflict resolution. It doesn't just find names. It understands why they are there.
No Data Residue
Your documents never stay on our infrastructure. What we save is a coordinate map — positions, not words. Useless without your file.
On-Premise Option
Air-gapped deployment via Docker. The entire pipeline runs locally — including the AI classifier. Your documents never leave your network.
Custom Entity Policies
Tell ObscuraDoc what is important in your domain. Medical conditions. Protocol numbers. Student IDs. It learns your vocabulary without retraining.
API-First
Every feature is available via REST API. Integrate it into your existing pipeline in an afternoon.
For Compliance Teams
Stop blocking AI adoption over data concerns. ObscuraDoc gives you a documented, auditable redaction layer so your teams can use AI tools without sending sensitive data to third-party models. Ready for the GDPR from day one.
For Developers
A REST API that returns a redacted document or a structured entity map. Your choice. Supports PDF and DOCX. Pluggable NER providers. Docker image available for self-hosted installations.
Common questions, concrete answers.
Everything you need to quickly understand how ObscuraDoc works, how it handles data, and where it fits in your document workflows.
What type of documents does ObscuraDoc support?
PDF and DOCX. You can upload them directly from the webapp with a drag and drop, or send them via API and receive the redacted document or a structured entity map — depending on how you want to integrate it into your workflow.
How does it avoid obscuring Napoleon Bonaparte but obscure John Doe?
It doesn't just look for textual patterns. Every entity found is evaluated in its context: who it is, what role it has in that document, whether it's a public reference or an identifiable person. Only then does it decide whether to obscure it.
Do the documents end up on your servers?
No. The files are processed and deleted. What we keep — only if you choose to — is an encrypted coordinate map: positions in the document, not words. Without the original file, it's useless even to us.
Can I use it without sending anything outside my network?
Yes. ObscuraDoc is distributed as a Docker container and runs entirely on-premise, AI included. Documents don't leave your infrastructure. It's the right choice if you have corporate policy constraints or operate in regulated sectors.
Is there an API to integrate it into our systems?
Yes. A REST endpoint, OpenAPI documentation included. You send the document, you receive the redacted one or the entity map. You can integrate it into an existing pipeline in half a day.
Who is it really for?
For those who need to use sensitive documents with AI tools without violating the privacy of those mentioned in those documents. Law firms, compliance teams, developers building AI products, school administration, healthcare facilities. If your problem is 'I can't send this file to ChatGPT', ObscuraDoc is the answer.
Ready to protect your sensitive data?
Choose a slot from the calendar for a quick intro call. We'll look at your document workflow and how to integrate ObscuraDoc.
Book a demo
Ready to protect your sensitive data?
Choose a slot from the calendar for a quick intro call. We'll look at your document workflow and how to integrate ObscuraDoc.
30-minute call. No email ping-pong.