Dati sensibili dentro.Documento pulito fuori.
Il motore che riconosce, comprende e censura nomi, codici fiscali e dati clinici in pochi secondi. Dati sensibili dentro, PDF redatto fuori.
Call da 30 minuti. Vediamo insieme il tuo workflow documentale.
Ogni strumento di redazione oscura i nomi. La maggior parte oscura anche quelli sbagliati.
I rilevatori PII standard sono ciechi al contesto. Trovano pattern, non comprendono il significato. Dagli in pasto un referto medico e oscureranno il nome del paziente. Dagli un saggio storico e oscureranno anche Napoleone. Questa non è redazione. È tirare a indovinare con un pennarello.
Standard Redactor
Rimuove sia i dati privati che il contesto storico, rendendo il testo incomprensibile.
ObscuraDoc
Protegge l'identità del paziente preservando in modo sicuro i riferimenti storici.
ObscuraDoc legge prima di oscurare.
La nostra pipeline combina il riconoscimento delle entità nominate (NER) con la classificazione contestuale. Ogni entità candidata viene valutata in base al contesto circostante prima che venga rimosso qualcosa. I personaggi pubblici restano. I riferimenti storici restano. I privati cittadini no. Il risultato è un documento pulito, non uno danneggiato.
Carica
Trascina il tuo PDF o DOCX. Nessun dato viene memorizzato sui nostri server.
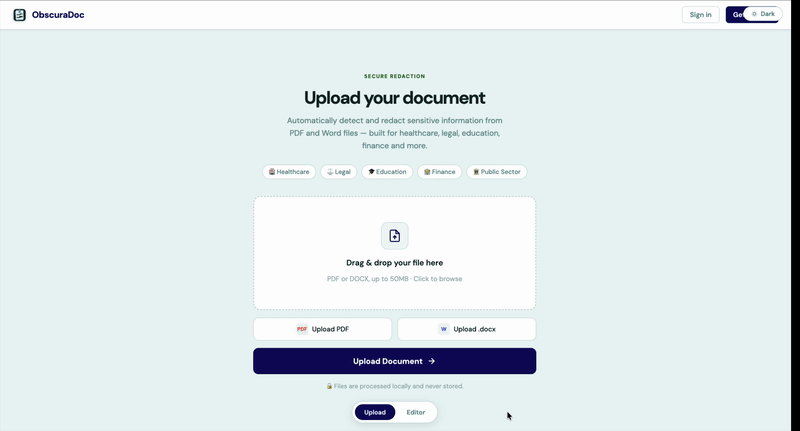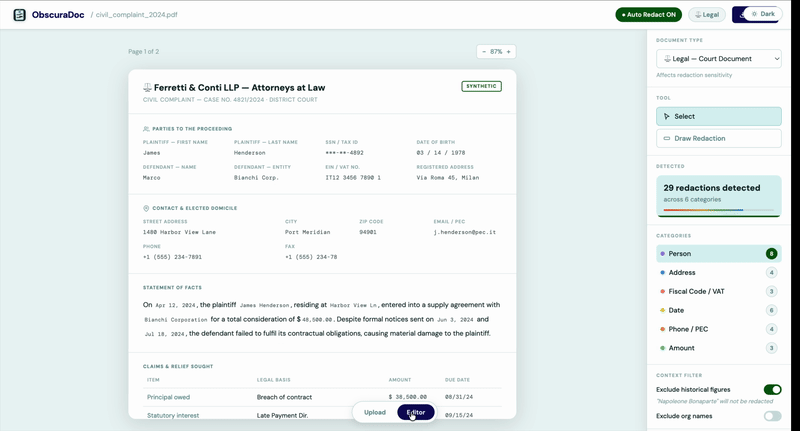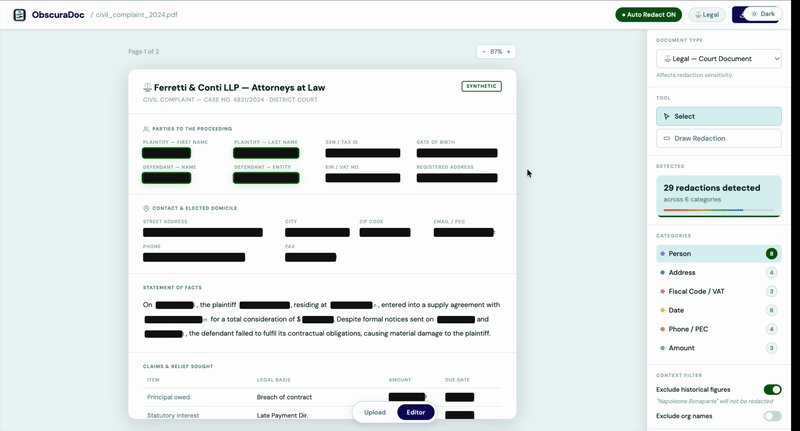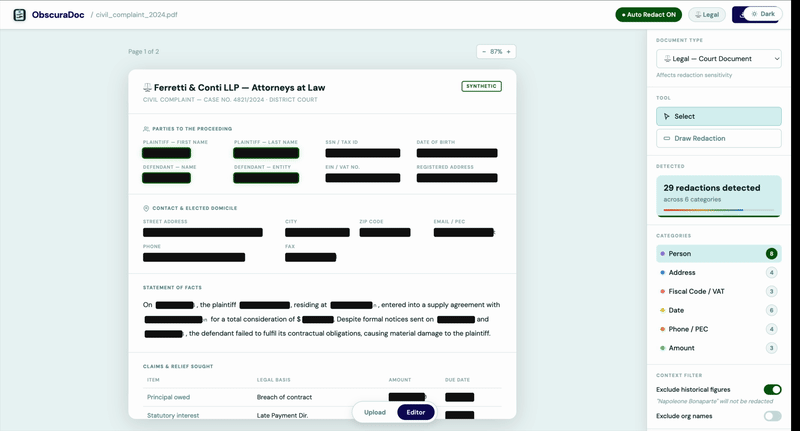
Rivedi
ObscuraDoc evidenzia ogni entità rilevata e la sua classificazione. Approvi, modifichi o sovrascrivi prima che venga rimossa una singola lettera.
Scarica
Ottieni il tuo documento redatto. Conserviamo solo una mappa crittografata delle coordinate, così puoi riapplicare le stesse redazioni in seguito senza ricaricare i dati.
Tutto ciò che serve, senza compromessi.
Classificazione contestuale intelligente
Alimentata da una pipeline multi-fase, NER, classificazione contestuale LLM e risoluzione dei conflitti. Non trova solo i nomi. Capisce perché sono lì.
Nessun residuo di dati
I tuoi documenti non si fermano mai sulla nostra infrastruttura. Ciò che salviamo è una mappa di coordinate — posizioni, non parole. Inutile senza il tuo file.
Opzione on-premise
Deploy air-gapped tramite Docker. L'intera pipeline gira localmente — incluso il classificatore AI. I tuoi documenti non lasciano mai la tua rete.
Policy personalizzate per entità
Dì a ObscuraDoc cosa è importante nel tuo dominio. Condizioni mediche. Numeri di protocollo. ID studenti. Impara il tuo vocabolario senza riaddestramento.
API-first
Ogni funzionalità è disponibile tramite API REST. Integralo nella tua pipeline esistente in un pomeriggio.
Per i team di compliance
Smetti di bloccare l'adozione dell'AI per problemi di dati. ObscuraDoc ti offre un layer di redazione documentato e verificabile, così i tuoi team possono usare strumenti AI senza inviare dati sensibili a modelli di terze parti. Pronto per il GDPR fin dal primo giorno.
Per gli sviluppatori
Un'API REST che restituisce un documento redatto o una mappa strutturata delle entità. A te la scelta. Supporta PDF e DOCX. Provider NER pluggabili. Immagine Docker disponibile per installazioni self-hosted.
Le domande più comuni, con risposte concrete.
Tutto quello che serve per capire in fretta come funziona ObscuraDoc, come gestisce i dati e dove si inserisce nei tuoi workflow documentali.
Che tipo di documenti supporta ObscuraDoc?
PDF e DOCX. Puoi caricarli direttamente dalla webapp con un drag and drop, oppure inviarli via API e ricevere il documento redatto o una mappa strutturata delle entità — a seconda di come vuoi integrarlo nel tuo workflow.
Come fa a non oscurare Napoleone Bonaparte ma a oscurare Mario Rossi?
Non cerca solo pattern testuali. Ogni entità trovata viene valutata nel suo contesto: chi è, che ruolo ha in quel documento, se è un riferimento pubblico o una persona identificabile. Solo dopo decide se oscurare.
I documenti finiscono sui vostri server?
No. I file vengono processati e cancellati. Quello che conserviamo — solo se lo scegli tu — è una mappa di coordinate crittografata: posizioni nel documento, non parole. Senza il file originale, è inutile anche per noi.
Posso usarlo senza mandare nulla fuori dalla mia rete?
Sì. ObscuraDoc si distribuisce come container Docker e gira interamente on-premise, AI inclusa. I documenti non escono dalla tua infrastruttura. È la scelta giusta se hai vincoli di policy aziendale o operi in settori regolamentati.
C'è un'API per integrarlo nei nostri sistemi?
Sì. Un endpoint REST, documentazione OpenAPI inclusa. Mandi il documento, ricevi il redatto o la mappa delle entità. Puoi inserirlo in una pipeline esistente in mezza giornata.
A chi serve davvero?
A chi deve usare documenti sensibili con strumenti AI senza violare la privacy di chi è citato in quei documenti. Studi legali, team compliance, sviluppatori che costruiscono prodotti AI, segreterie scolastiche, strutture sanitarie. Se il tuo problema è 'non posso mandare questo file a ChatGPT', ObscuraDoc è la risposta.
Pronto a proteggere i tuoi dati sensibili?
Scegli uno slot dal calendario per una rapida call conoscitiva. Vedremo insieme il tuo workflow documentale e come integrare ObscuraDoc.
Prenota una demo
Pronto a proteggere i tuoi dati sensibili?
Scegli uno slot dal calendario per una rapida call conoscitiva. Vedremo insieme il tuo workflow documentale e come integrare ObscuraDoc.
Call da 30 minuti. Nessun ping-pong via email.